
The BDNYC team presented a variety of posters and talks at the 243rd meeting of the American Astronomical Society in New Orleans from January 7th to 11th, 2024. Check out this year’s amazing projects!
Continue readingThe BDNYC team presented a variety of posters and talks at the 243rd meeting of the American Astronomical Society in New Orleans from January 7th to 11th, 2024. Check out this year’s amazing projects!
Continue readingThe BDNYC team is proud to announce that team member Dr. Mark Popinchalk successfully defended his thesis in the Physics PhD program at the City University of New York Graduate Center (CUNY Grad Center) this July 2023.
The BDNYC team is thrilled to congratulate Dr. Jackie Faherty, who has been awarded a prestigious five-year CAREER grant from the National Science Foundation to develop and present the most complete map of our solar neighborhood ever generated.

The BDNYC team is pleased to announce that Dr. Daniella Bardalez Gagliuffi has accepted an Assistant Professor position at Amherst College, and Dr. Johanna Vos has been awarded a Royal Society – Science Foundation Ireland University Research Fellowship.


As one of the last large programs carried out by the Spitzer Space Telescope (Spitzer GO 14128 led by PI J. Faherty) prior to its retirement in 2020, a new survey for photometric variability in young, low-mass brown dwarfs will now pave the way for future searches for cloud-driven variability in directly-imaged exoplanets with next-generation telescopes.
Dr. Johanna Vos and a team of investigators have recently published the findings of their survey in a paper titled “Let the Great World Spin: Revealing the Stormy, Turbulent Nature of Young Giant Exoplanet Analogs with the Spitzer Space Telescope,” with promising results.
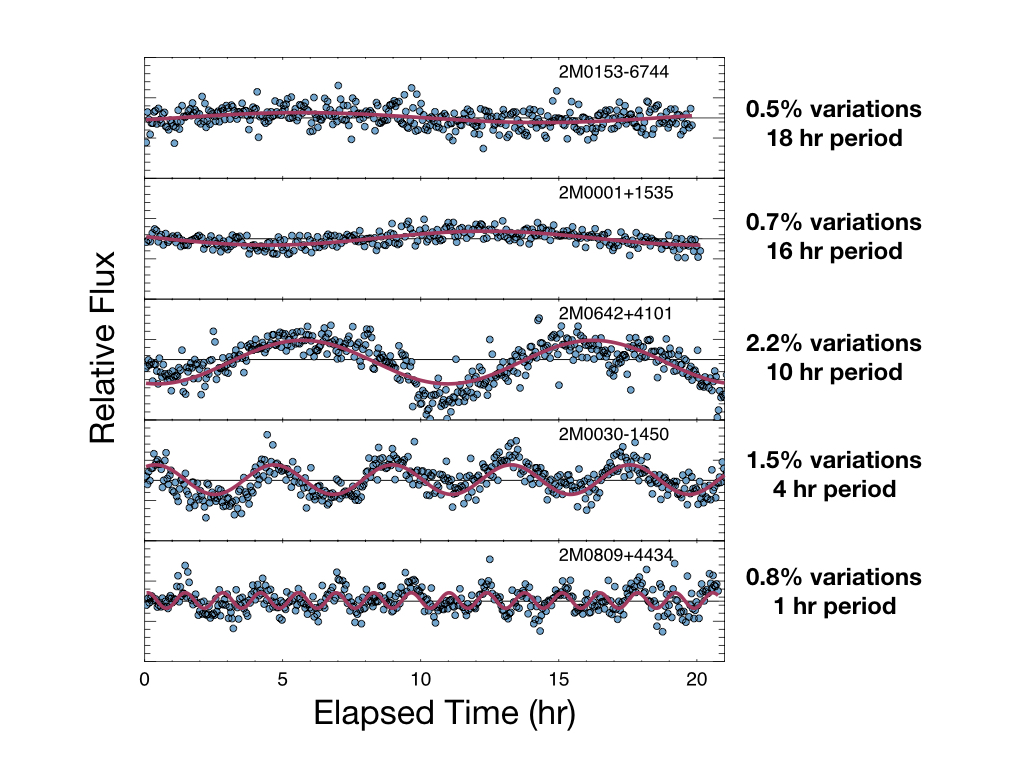
The survey detected new variable objects with a range of rotation periods and variability amplitudes, across a variety of temperatures. Blue points show the measured brightness and the pink line shows the best fit variable model.
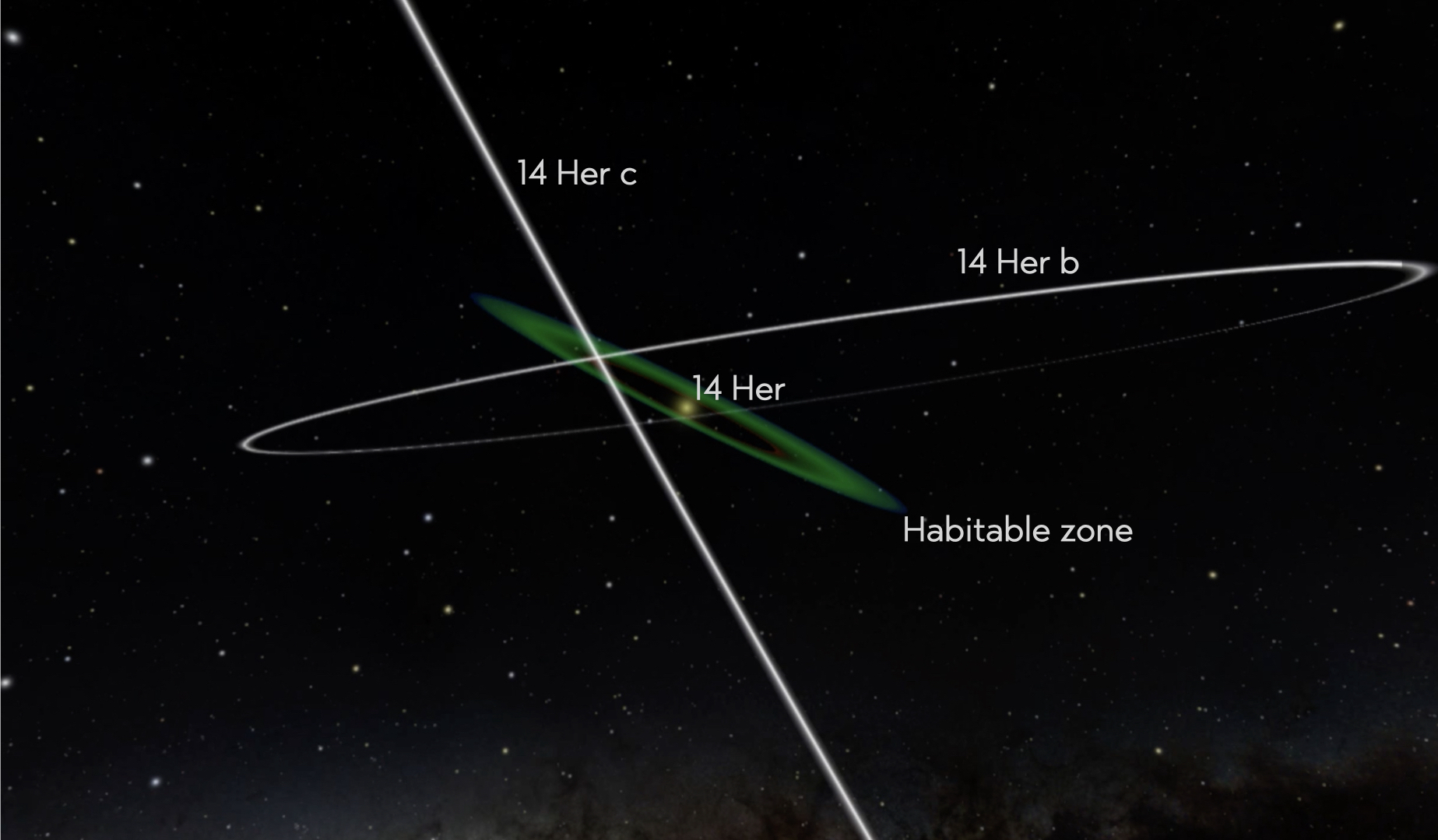
The X-shaped set of orbits in 14 Her.
The forensic evidence left in the 14 Her giant planetary system suggests an active dynamical past. Two giant planets, several times more massive than Jupiter, in highly eccentric orbits around a solar-type star were found orbiting at nearly right angles to each other. In the recently published paper “14 Her: a likely case of planet-planet scattering,” Daniella Bardalez Gagliuffi—a senior member of the Brown Dwarfs in New York City Research Group (BDNYC) based at the American Museum of Natural History (AMNH)—along with a team of orbital investigators measured the full architecture of the two-planet system around the nearby K0 dwarf 14 Herculis, with some surprising results.
The BDNYC team is thrilled to congratulate Dr. Jackie Faherty and Dr. Kelle Cruz for both being named Fellows of the American Astronomical Society (AAS) in 2022.

Kelle Cruz and Jackie Faherty
The BDNYC team’s project proposal entitled “Read Between the Lines: Determining Atmosphere and Bulk Compositions for Planetary Mass Objects Using Spectral Retrievals” was selected for a NASA Exoplanets Research Program (XRP) grant.
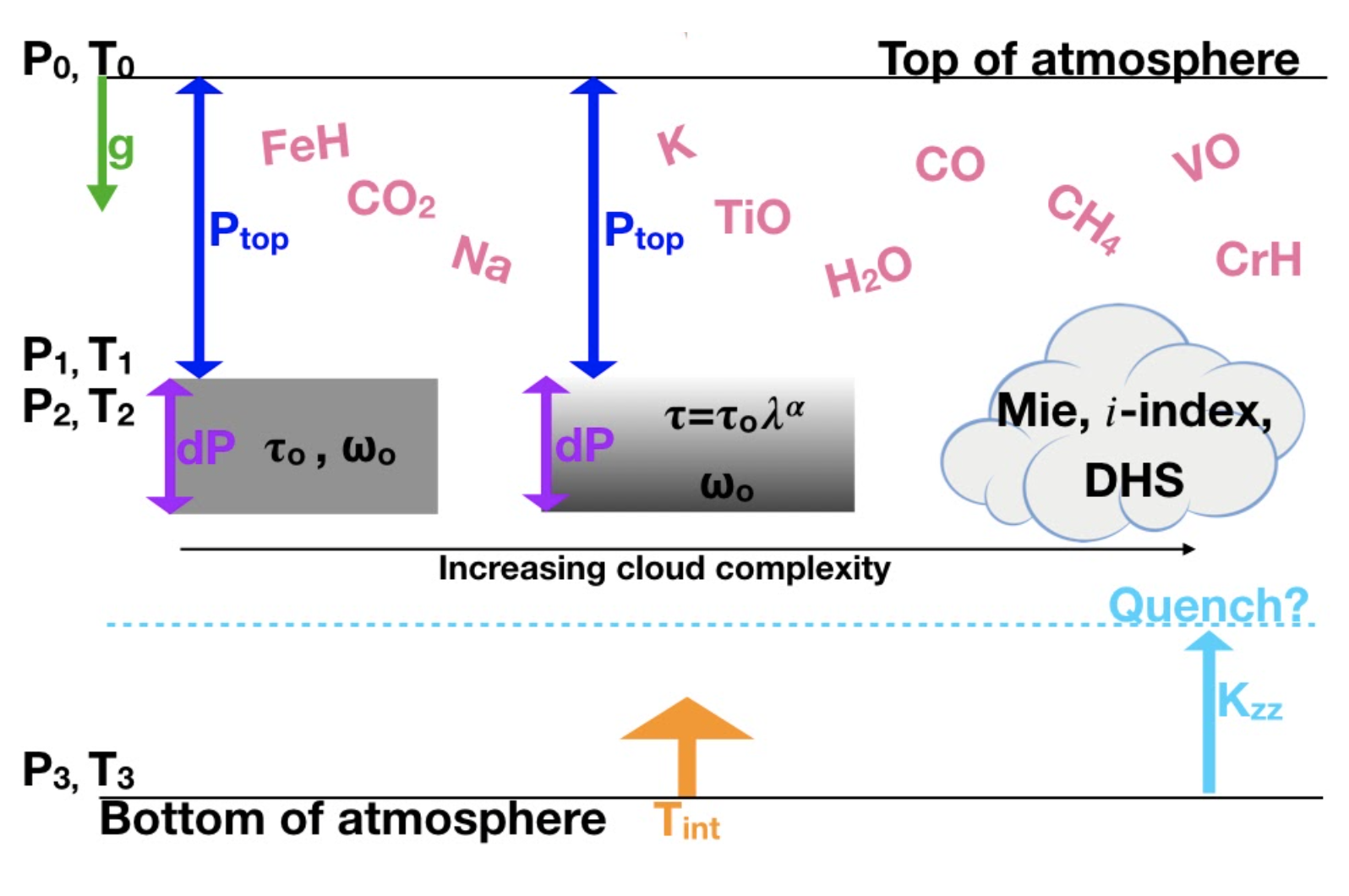
Parameters to consider in spectral retrievals of directly-imaged exoplanet atmospheres. These include a parameterized P-T profile, gas species (pink), various cloud models (center grey), and a disequilibrium chemistry option (aqua).
BDNYC member and fourth year CUNY graduate student Mark Popinchalk has recently posted a first-author paper which explores the tricky territory of M dwarf rotation rates.
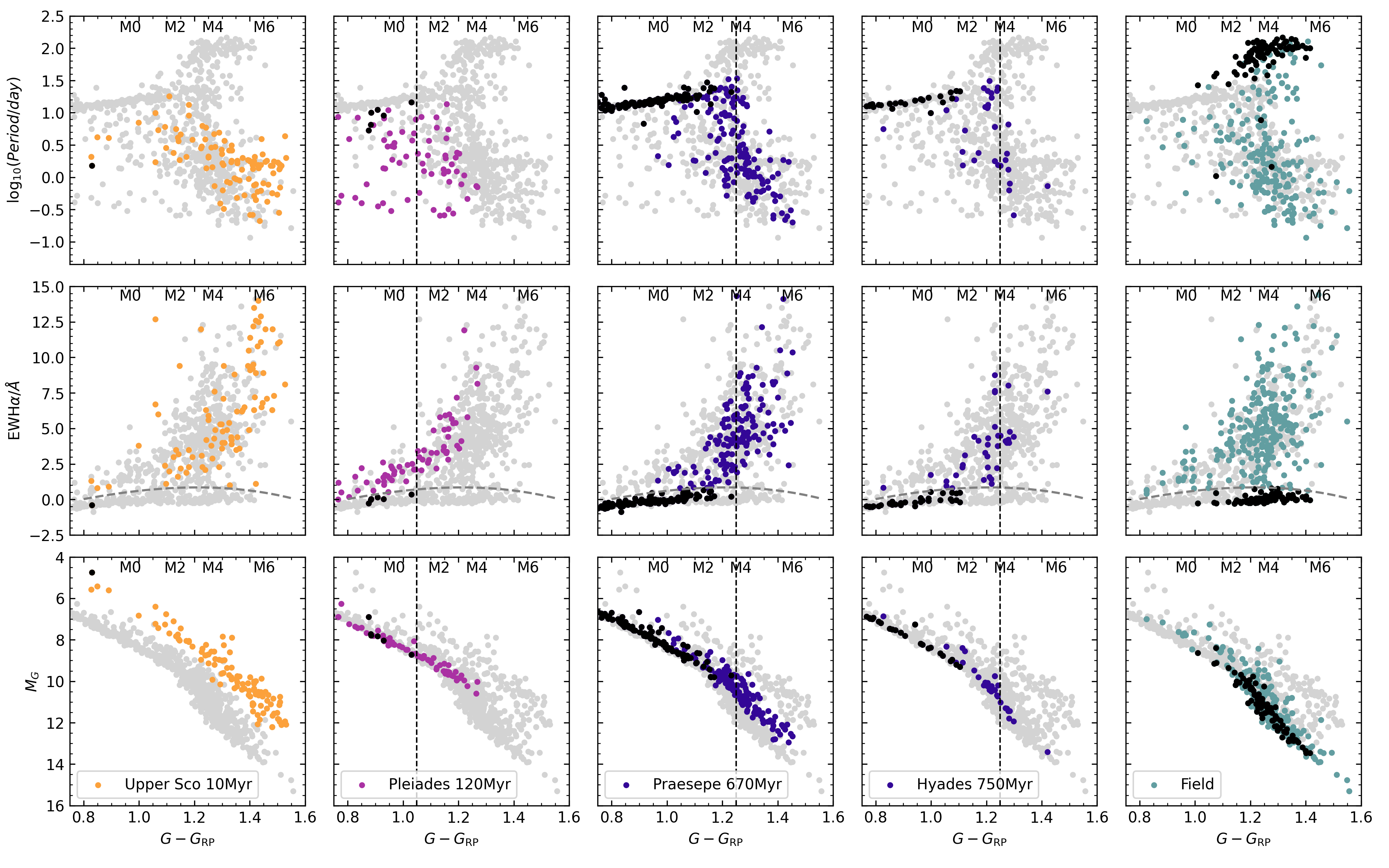
Figure 1: the complexity of the evolution of M dwarfs at these ages.
The BDNYC team is thrilled to announce that our artist-in-residence, Janani Balasubramanian, has been awarded a 2021 New York Foundation for the Arts (NYFA) Fellowship, for an excerpted draft from their brown dwarf-themed novel, Harold & Okno.

Janani Balasubramanian